Claude Code ソースコード解説シリーズ 第2章: ReAct メインループ
Claude Code の ReAct ループを分解し、query.ts がモデルの継続行動をどう駆動するかを理解します。
『Claude Code ソースコード解析シリーズ』第2章|ReAct メインループ
前回は Claude Code をいくつかのレイヤーに分解しました。Model API は判断を担い、QueryEngine はメインループを推進し、Tools は実際のエンジニアリング環境と接触し、Context / State はタスクの継続性を保つ――という構造です。
今回はさらに深掘りし、まず中核となるレイヤーを見ていきます。query.ts が、一度のモデル呼び出しを、持続的に行動できる Agent Run へと拡張する仕組みです。
引き続き前回と同じ例を使います。
このプロジェクトでテストが失敗している原因を調べて、修正してほしい。前回すでに述べたとおり、モデルはそれ自体でファイルを読んだり、コマンドを実行したり、タスク状態を管理したりはできません。ここで繰り返すことはしません。問題はここからです。
Claude Code は、モデルを制御されたループの中で、判断・行動・結果の吸収を繰り返させ、タスクが本当に前に進むまで回し続けるにはどうしているのか?
これこそが ReAct の解決する課題です。
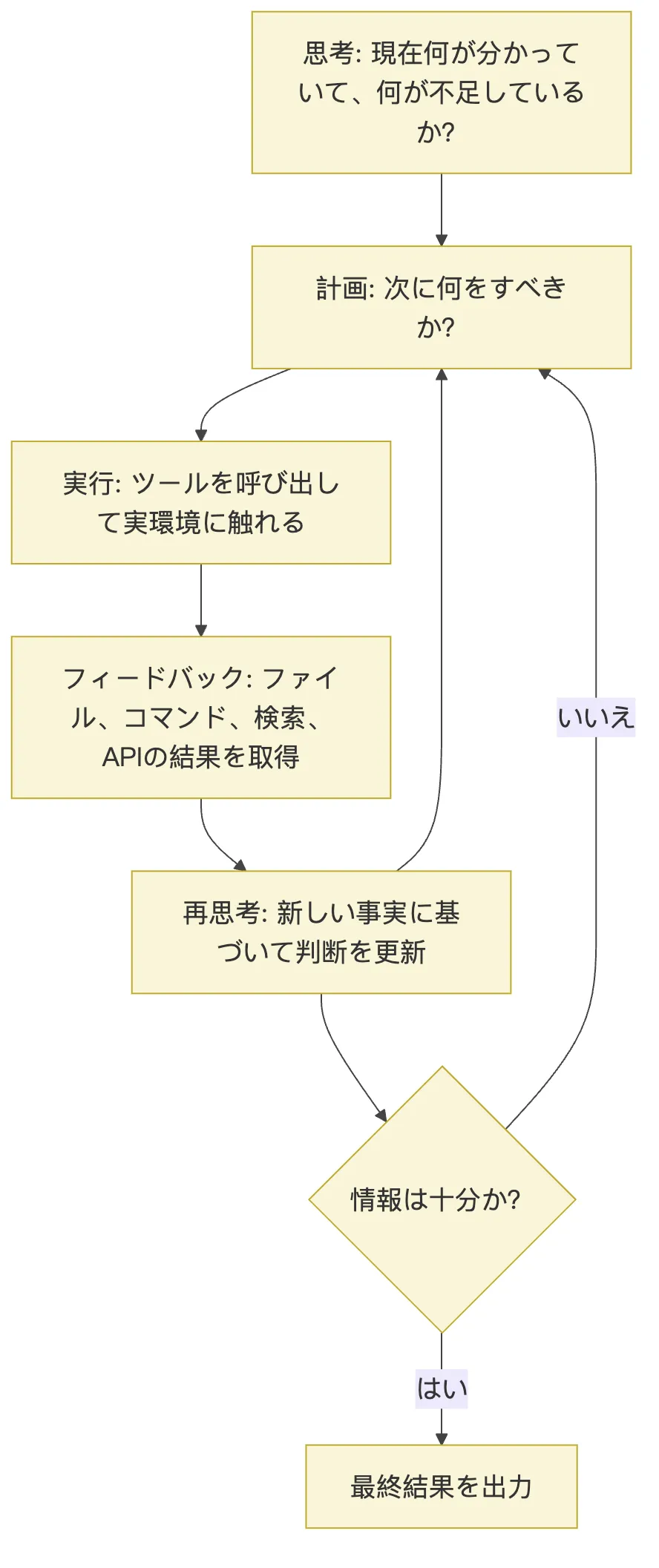
文献によってはこのプロセスを ReAction と表記することもあります。本記事では用語のブレを避けるため、ReAct に統一します。まずは略語を覚えるよりも、最小のクローズドループを頭に入れてください。
現在の状況を判断する
→ 次に何をするか決める
→ 実際に実行する
→ 結果を得る
→ 新しい結果をもとに再判断する図にすると次のようになります。
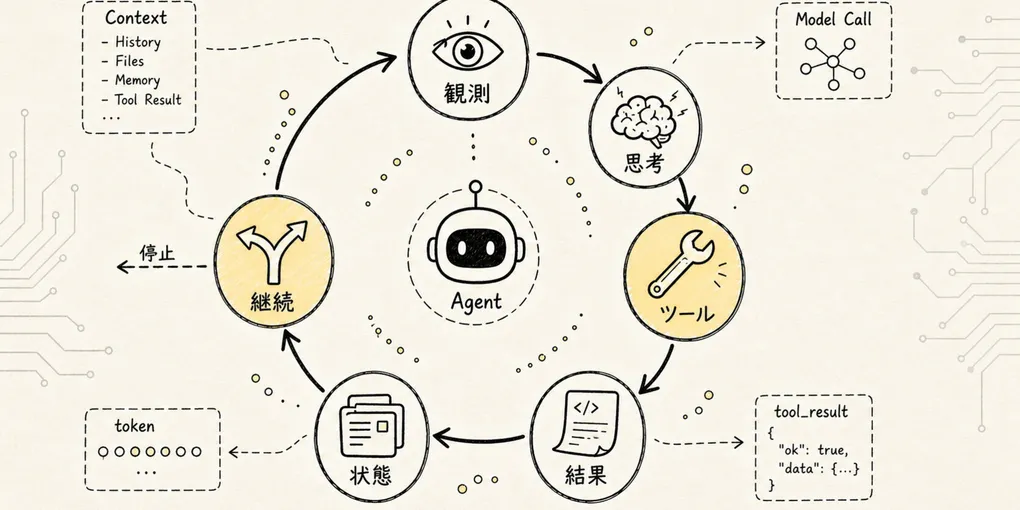
Claude Code の query.ts がやっているのは、このクローズドループをエンジニアリングとして実装することです。モデルはまずコンテキストに基づいて判断し、それから行動に移るかどうかを決めます。行動の結果がコンテキストに書き戻されると、モデルは次の判断ラウンドに進みます。
図のなかで本当に重要なのは派手な概念ではなく、右側にある素朴なステートマシンです。
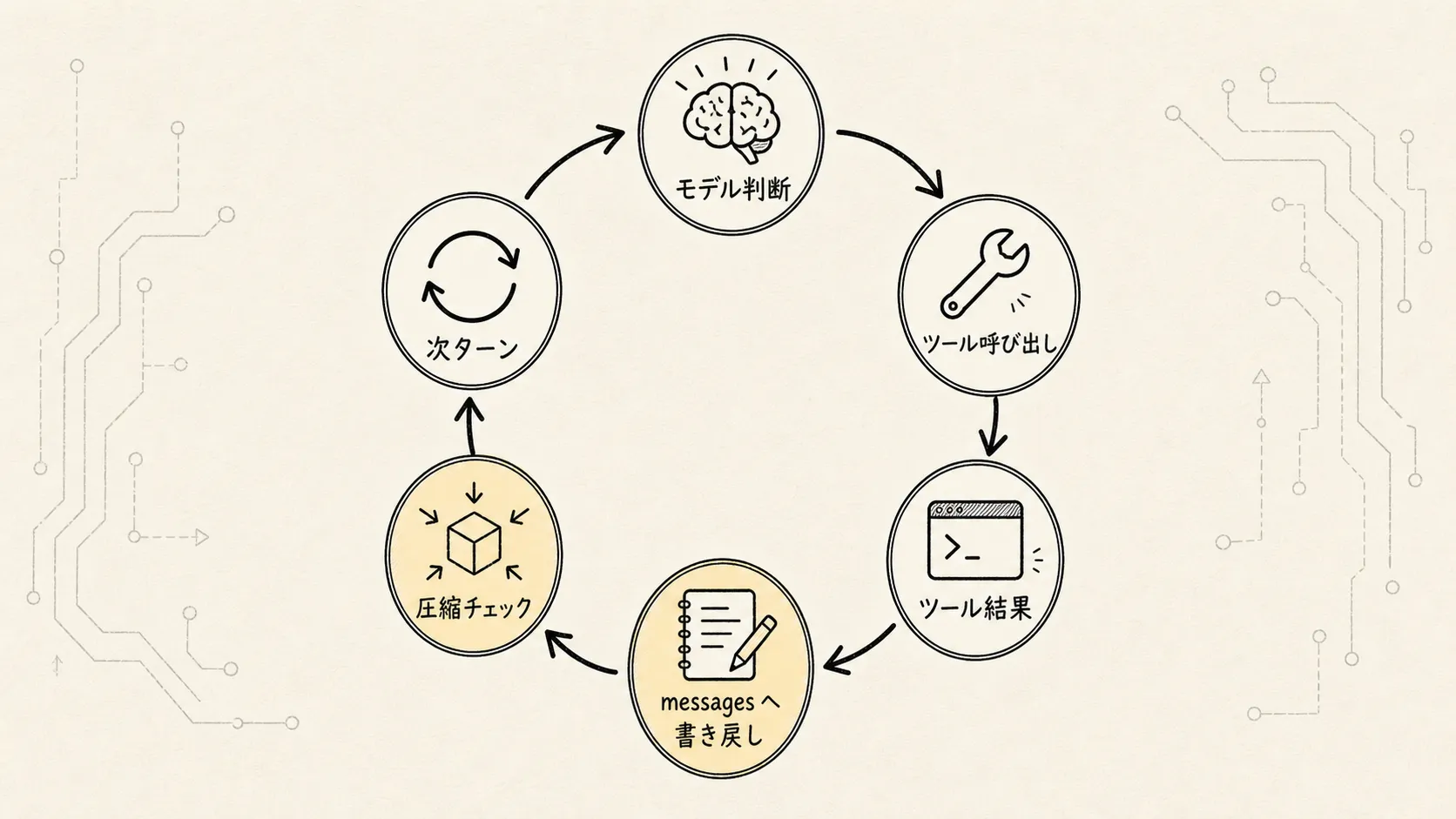
Query を構築
→ Model API にリクエスト
→ 返却結果をパース
→ ツール呼び出しの有無を判定
→ なければ結果を返す
→ あればツールを呼び出す
→ ツールの結果を messages に追加
→ 圧縮の要否をチェック
→ 次の Query ラウンドへ戻るこのループこそが、前回のアーキテクチャ図が実際に動き出す部分です。
とはいえ、これを単なる while ループと捉えてしまうと、もう一段見落とすことになります。轩辕代码(Xuanyuan Code)の解説に倣えば、QueryEngine のより正確な位置づけは「1回限りのリクエストハンドラ」ではなく、「セッションレベルのタスクオーケストレータ」です。これは届いたメッセージに対してその場で一度だけ動くのではなく、一つの会話を中心に状態を長期保持し、モデル・ツール・権限・コンテキスト・圧縮をすべて束ねて回し続けます。
そのため、この記事では2つのレイヤーを同時に押さえる。
query.ts のレイヤー:ReAct の状態遷移がラウンドごとにどう発生するか。
QueryEngine のレイヤー:セッション全体で状態・ツール・権限・リソースがどう継続的にオーケストレーションされるか。前者は「ループがどう回るか」を説明し、後者は「そのループがなぜ複数ラウンドのタスクにわたって安定して存続できるのか」を説明する。
1. なぜメインループは Model API を一度しか呼び出せないのか?
まず、最もシンプルなケースから考えてみる。
ユーザーがこう尋ねる:
useEffect とは何か説明して。プログラムはこの質問をモデルに送り、モデルが直接回答を生成する。それで終わりだ。
しかし、ユーザーがこう尋ねた場合はどうか:
この React プロジェクトが起動しない。直してほしい。モデルは最初のターンで答えを知らないのが普通だ。少なくとも、さらに多くの事実を取得する必要がある:
プロジェクト構造は?
package.json のスクリプトはどう書かれている?
起動コマンドのエラー内容は?
関連するソースコードはどこ?
修正後にテストは通るか?これらの事実は、モデルのパラメータにも、ユーザーの一言にも含まれていない。それらは実際のエンジニアリング環境に存在する——ファイルシステム、シェル、Git、テストフレームワーク、ログ出力、依存関係の設定といった場所だ。
そのため、エージェントにはもう一段階の仕組みが必要になる:
モデルが不足している情報を判断する
-> ツール呼び出しを発行する
-> プログラムがツールを実行する
-> 結果をモデルに返す
-> モデルが新しい事実に基づいて再度判断するこれが ReAct ループの登場する理由である。
フローを複雑にしたいからではない。実務的なタスクは、そもそも一度の応答で解決できるものではないのだ。むしろ、継続的に修正を重ねるプロセスに近い。まず方向性を推測し、現場で証拠を集め、その証拠に基づいて次の一手を調整する。
本番障害のトラブルシューティング経験があるエンジニアなら、この流れはよく馴染むはずだ。まず仮説を立て、現場で証拠を集め、その証拠に基づいて次の一手を修正する。
2. ReActは「モデルが自ら操作する」のではなく、「モデルが意図を提示する」
ここは非常に誤解しやすいポイントです。
モデルは実際には自らファイルを読んだり、コマンドを実行したり、コードを書き換えたりしているわけではありません。
モデルができるのは、一種の「行動意図」を出力することです。たとえば:
package.json を読み取る必要がある。
handleEnter を検索する必要がある。
npm test を実行する必要がある。
あるファイルを編集する必要がある。実際に手を動かすのは Claude Code のホストプログラム、つまり外層の QueryEngine、Tools システム、権限システムです。
したがって、より正確な役割分担は次のようになります:
モデルは次に何をすべきかの判断を担当する。
Claude Code はそれを実行してよいか、どのように実行するか、実行後にどう記録するかを担当する。これこそが、Claude Code が単なる「モデルにシェルをつなぐ」だけの代物ではない理由です。
仮にモデルにシェルコマンドをそのまま出力させて直接実行させた場合、システムはその操作のセマンティクスをまったく把握できません。権限制御、監査、エラーリカバリ、コンテキストへの反映、すべてが管理不能になります。
ツールシステムはアクションを構造化されたイベントに変換します:
ツール名:Read
パラメータ:対象ファイルパス
権限:読み取り専用
結果:ファイル内容またはエラー
反映:tool result として messages に書き戻すこの仕組みにより、モデルは推論を担当し続ける一方で、アクションは制御可能な工学的フレームワークの中に収められます。
役割分担を一言で言えばこうです:モデルは判断を、ツールは実世界との接点を、QueryEngine は判断とアクションを持続可能なループとして組織化する。
3. query.ts のステートマシン:中核は関数ではなく State
図の左側には query.ts の State 構造が示されている。ここでまず押さえておきたいのは:
Claude Code のメインループは、散在するグローバル変数で動いているのではなく、統一された状態オブジェクトを中心に進行する。
簡略化すると次のような形だ:
interface State {
messages: MessageParam[]
toolUseContext: ToolUseContext
turnCount: number
shouldAutoCompact: boolean
autoCompactTracking: {
consecutiveFailures: number
totalMessages: number
}
aborted: boolean
}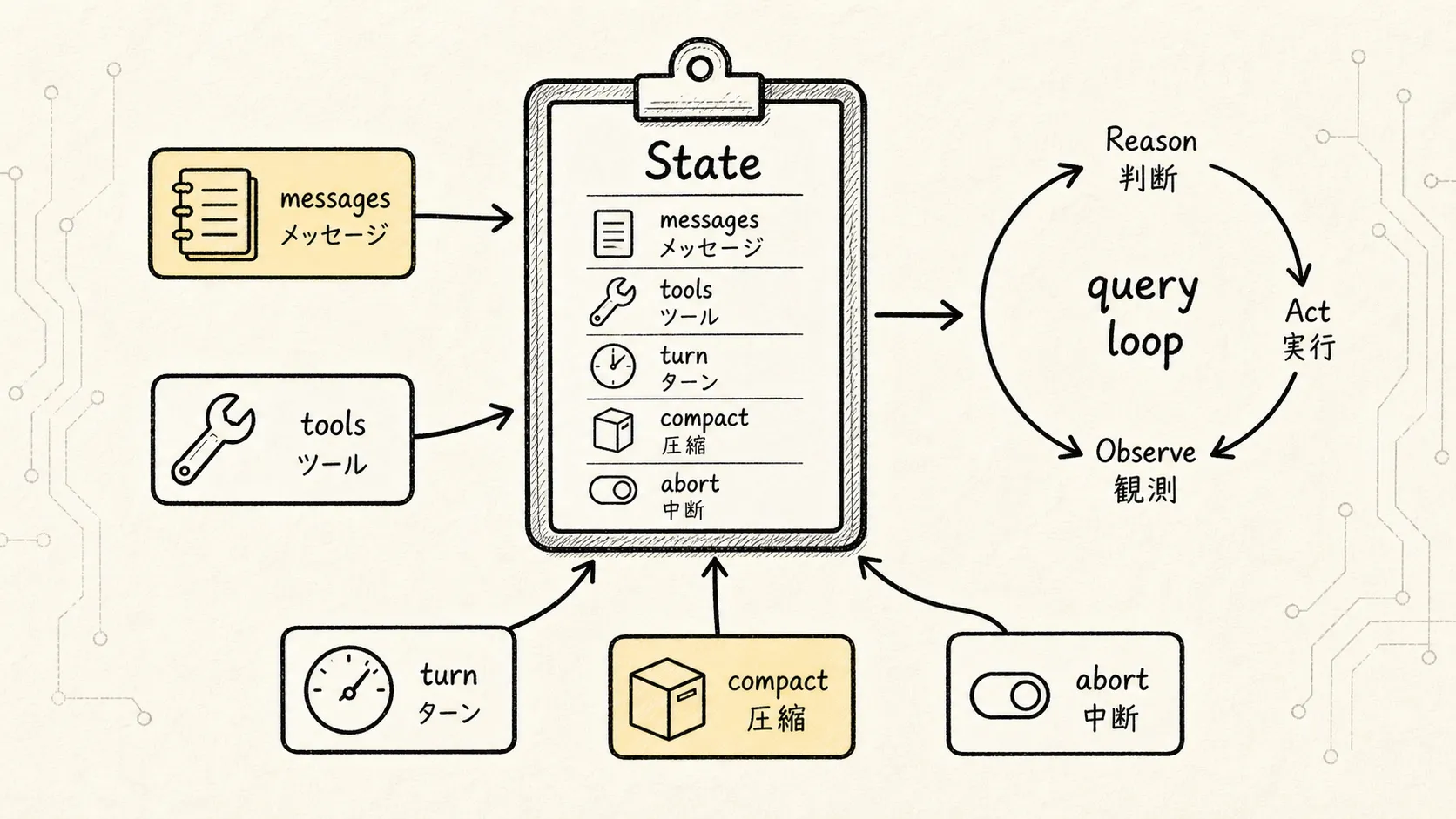
これらのフィールドが、ReAct の閉ループを理解するための鍵となる。
1. messages:エージェントの短期ワーキングメモリ
messages は単なるチャット履歴ではない。
エージェントループにおいて、これはむしろ「現場の帳簿」に近い役割を果たす:
ユーザーが直前に何を言ったか
モデルが前のターンで何を判断したか
モデルがどのツール呼び出しを開始したか
ツールがどのような結果を返したか
圧縮後にどのような要約が保持されたかモデル自体は、過去に起きたことを自動的に覚えているわけではない。Model API を呼び出すターンごとに、Claude Code は現在に関連する履歴を再度パッケージ化してモデルに渡す必要がある。
つまり messages の役割は次の一点に尽きる:
複数ターンのアクションを、モデルが次のターンで参照できるコンテキストに変換すること。
messages がなければ、ターンごとのモデル呼び出しはすべて、記憶を失った状態でゼロからやり直すことになる。
2. toolUseContext:このターンで使える「手足」
toolUseContext はツール環境そのものである。
それは単なるツール一覧ではなく、メインループに対して次の情報を伝えている。
現在どのツールが利用可能か?
各ツールの入力スキーマは何か?
ツール実行時に必要なコンテキストは?
結果はどのようにメッセージ化すべきか?
どの操作に権限制御が必要か?ReAct の Act は抽象的な行動ではない。ツールシステムによって制約された具体的な行動である。
同じ「ファイルを見る」でも、Read ツールを通すのと直接 cat を叩くのとでは、工学的な意味がまったく異なる。前者は追跡可能で、制限可能で、構造化された埋め戻しが可能。後者はただの文字列であり、何か起きても何をしたのかすら分からない。
つまり、ツールは動けばいいというものではない。追跡でき、制限でき、埋め戻しできなければならない。
3. turnCount:これはマルチターンシステムであり、単発リクエストではない
turnCount はループが何周したかを記録する。
一見地味なフィールドだが、ある根本的な事実を露わにしている。
Claude Code は設計段階から、タスクが複数ターンにわたることを前提としている。
「モデルに一度だけ問い合わせ、たまたま正解できるかどうかに賭ける」わけではない。モデルが複数ターンの中で徐々に情報を集め、ツールを呼び出し、判断を修正していくことを許容している。
turnCount は無限ループの防止、ログ集計、縮退戦略の発動にも使える。成熟したエージェントは、自分がどれだけ回っているかを把握していなければならない。そうでなければ、失敗経路の中で容易にその場で空回りしてしまう。
だからこそ、成熟したエージェントには必ずターン数、予算、終了条件が必要だ。これらの境界がなければ、マルチターンループは容易にその場での空回りに陥る。
4. shouldAutoCompact:コンテキストは膨張する、圧縮はメインループに組み込まれなければならない
エージェントがツールを呼び出し始めると、messages は急速に長くなる。
大きなファイルを読み、テストを一度実行し、検索結果をまとめて取得する。そのすべてが大量の情報をメッセージ履歴に書き戻す。短いタスクなら問題ないが、長いタスクはすぐにコンテキストウィンドウに衝突する。
したがって shouldAutoCompact は、あれば嬉しい付加的な最適化ではない。長期的なタスクを扱うエージェントにとって必須のキャパシティ管理シグナルである。
これが答えているのは次の問いだ。
現在のメッセージ履歴はすでに長すぎるか?
古い内容を要約に圧縮する必要があるか?
圧縮が連続して失敗していないか?
圧縮前後でメッセージ量はどう変化するか?参考図で「ツール結果を messages に追加」した直後に「圧縮が必要かチェック」が続く理由はここにある。
コンテキストを実際に膨張させるのは、往々にしてツール結果だからだ。
5. aborted:エージェントも安全に中断できなければならない
現実のエンジニアリングタスクは、毎回スムーズに完了するとは限らない。
ユーザーがキャンセルするかもしれないし、コマンドが停止するかもしれない。ツールがタイムアウトしたり、権限が拒否されたりすることもある。
aborted は、このループが外部から中断されうることを表している。これはつまり、Agent のメインループは「どう始めるか」「どう成功させるか」だけでなく、「どう停止するか」も考慮しなければならない、ということを示唆している。
安全に停止できない Agent は、能力が高いほどリスクも大きくなる。
能力の高い Agent であればあるほど、きれいに停止できることが求められる。
4. QueryEngine の視点:管理するのはセッションであって、単一リクエストではない
ここまで、query.ts における 1 回の ReAct ステートマシンがどのように回るかを見てきた。しかしソースコードを読む際には、さらにもう一段外側を見る必要がある。このループが依存する長期的な状態を保持しているのは誰なのか?
答えは QueryEngine だ。
轩辕コード(Xuanyuan Code)の記事には、非常に重要なソースコードリーディングの視点が示されている。QueryEngine は conversation(会話)単位で存在するという判断である。これは極めて重要な指摘だ。つまり QueryEngine は使い捨てのリクエストハンドラではなく、セッションオブジェクトだということだ。
単一リクエストのハンドラが通常気にするのは、次のようなことだ。
入力は何か?
何を返すべきか?
今回の呼び出しは終了したか?一方、セッション単位のオーケストレータが気にするのは、次のようなことだ。
履歴メッセージをどのように追加し続けるか?
これまでに拒否された権限はどれか?
どのファイルを既に読み込んだか?
現在のターンと累積 usage はいくつか?
どの skill を発見したか?
どの memory をロード済みか?
現在のタスクは中断されているか?そのため、QueryEngine にはターンをまたぐ多数の状態が存在する。たとえば次のようなものだ。
type ConversationRuntimeState = {
messages: Message[]
abortController: AbortController // 外部からのキャンセル信号を扱うコントローラ
permissionDenials: PermissionDenial[]
totalUsage: Usage
readFileCache: FileStateCache
discoveredSkills: Set<string>
loadedMemoryPaths: Set<string>
}これらのフィールドは、これが「プロンプトをモデルに転送する」だけの薄いラッパーではなく、ひとつのセッションの実行現場を維持するものであることを示している。
両者の関係は次のように整理できる。
QueryEngine :セッションレベルのランタイム。長期的なリソースと状態の保持を担う。
query.ts ループ:タスク推進機構。Query の構築、モデル呼び出し、ツール実行、メッセージの埋め戻しをターンごとに担う。State はある 1 回のループにおける作業スナップショットであり、QueryEngine はセッションの背後にあるスケジューリングセンターに近い存在だ。
この視点を加えることで、ReAct は単なる「モデルがツール呼び出しを継続するかどうか」という小さなループではなく、完全なタスクライフサイクルの一部として捉えられるようになる。
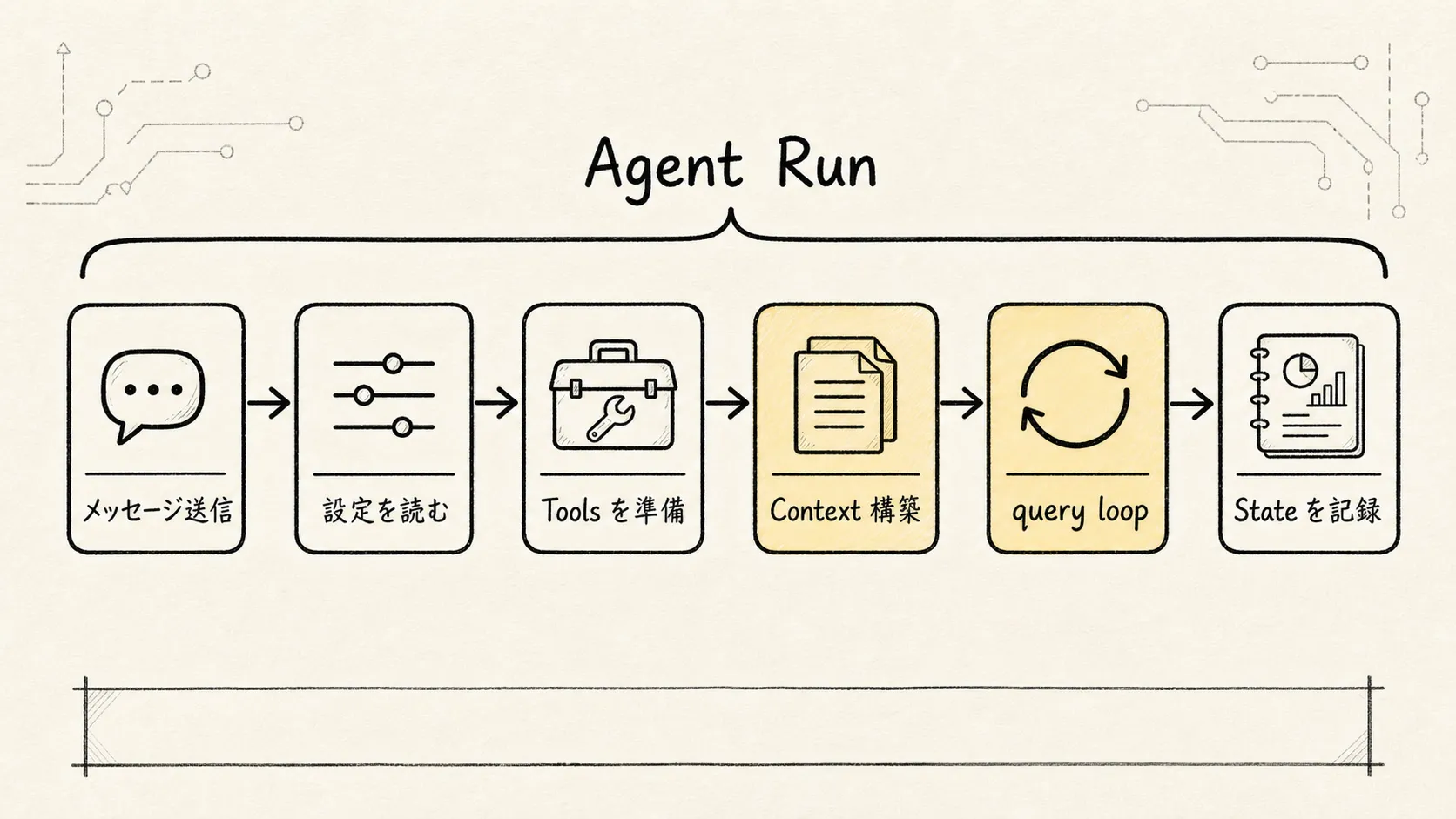
5. submitMessage():Agent Run を実際に開始するエントリポイント
ユーザーのアクションを起点にコードを追っていくと、メッセージが送信されるたびに呼ばれる本命のエントリポイントは、多くの場合 submitMessage() のようなメソッドに行き着く。
このメソッドは、一般的なバックエンドのエンドポイントのように単一の prompt だけを受け取るのではなく、ランタイムリソースの一式をまとめて読み取り、準備する。
現在のカレントワーキングディレクトリ(cwd)
利用可能なツール群
スラッシュコマンド
MCP クライアント
thinking 設定(拡張推論モードの有効/無効)
最大ターン数
予算上限
セッション永続化の状態つまり submitMessage() の本質は「一回のチャットリクエストを投げる」ことではなく、
1 回の Agent Run を開始することなのである。
1 回の Run の中でおおよそ実行される内容は次のとおり。
現在の設定とセッション状態の読み取り
作業ディレクトリとセッション環境のセットアップ
ツール権限の判定ロジックのラップ
システムプロンプトとコンテキストの準備
下位レイヤーのクエリループの呼び出し
モデル出力の処理中におけるツール呼び出しのハンドリング
ツール実行結果のセッション履歴への書き戻し
使用量・コスト・境界状態の集計query.ts に実装された ReAct ループは「タスクをどのように前に進めるか」という中核ロジックに過ぎない。submitMessage() と QueryEngine は、その中核を実際の Claude Code セッションの中に組み込んで走らせる責務を負っている。
ここにこそ、最小構成の Agent Demo と比べたときの Claude Code の工学的な深みがある。Demo が示すのはたいてい「モデルがツールを呼び出せる」という一点だが、QueryEngine が保証しなければならないのは次のような事柄だ。
今回のツール呼び出しは許可されるべきか?
その結果は次のターンのモデル入力に戻せるか?
失敗時に復旧できるか?
長期セッションで状態が破綻しないか?
コンテキストと予算が制御不能に陥らないか?本物の Agent エンジニアリングの複雑さは、こうした一見すると地味な部分に潜んでいる。
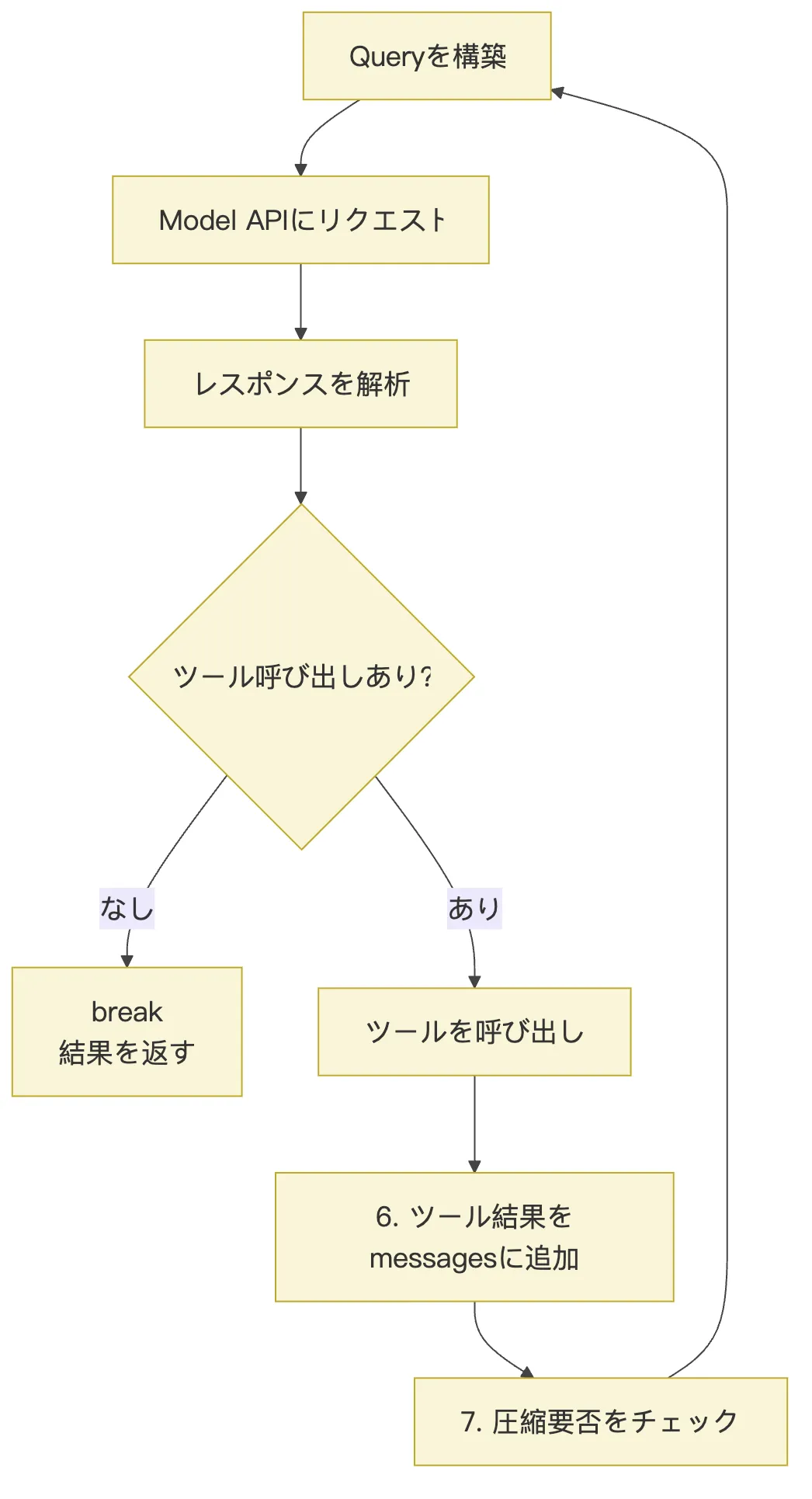
6. 右側のフローをコードに落とし込む:while ループの中で実際に何が起きているのか?
参考図の右側は、次のような簡略化した疑似コードに変換できます。
while (!state.aborted) {
const query = buildQuery(state)
const response = await requestModelAPI(query)
const parsed = parseModelResponse(response)
if (!parsed.hasToolUse) {
return parsed.finalAnswer
}
const toolResults = await runTools(
parsed.toolUses,
state.toolUseContext,
)
state = appendToolResultsToMessages(state, response, toolResults)
state = maybeAutoCompact(state)
state = nextTurn(state)
}この疑似コードには三つの重要なポイントがあります。
第一に、buildQuery(state) は単にユーザーの質問を結合するだけではありません。現在の State に基づいて、メッセージ履歴、システムプロンプト、利用可能なツール、コンテキストの要約などを含む、そのターンのモデル入力を構築します。
第二に、requestModelAPI(query) の戻り値は必ずしも最終的な回答とは限りません。テキストの場合もあれば、ツール呼び出しのリクエストを含む場合もあります。
第三に、ループが終了するのは、モデルがツールを要求しなくなったときだけです。モデルがツールを必要とする限り、Claude Code はツールの実行、結果の埋め戻し、次のターンへの移行を続けます。
つまり、while(true) は単なる無思考な無限ループではありません。
実際の終了条件は次のとおりです。
モデルがツールを要求しなくなった
またはタスクが中断された
または工学的な上限、エラー、権限ブロックに達したこれが Agent Loop の鼓動です。
(ソースコードを読む際は、buildQuery、parseModelResponse、maybeAutoCompact の三つの関数にブレークポイントを仕込むとよいでしょう。これらはそれぞれ「入力をどう構成するか」「出力をどう解釈するか」「状態をどう管理するか」に対応しており、この三つを押さえれば、処理の幹が見えてきます。)
7. 「ツール呼び出しがあるか?」がマシン全体の最も重要な分岐点
参考図には菱形の判定がある:
ツール呼び出しがあるか?このステップは一見単純だが、現在のターンの意味を決定づける。
ツール呼び出しがない場合、モデルは現在の情報で十分と判断し、最終回答を返せる:
いいえ -> break -> 結果を返すツール呼び出しがある場合、モデルは情報がまだ足りないと判断し、外部世界での調査が必要になる:
はい -> ツールを呼び出す -> messages に書き戻す -> 次のターンへツール呼び出しは単なる付加機能ではない。Claude Code を「回答モード」から「行動モード」に切り替えるスイッチなのだ。
通常のチャットボットは、たいてい最初のケースで止まる。テキストを生成して終わりだ。
一方、Agent は二番目のケースを必ずサポートしなければならない。モデルが「まだ知らない」と認め、ツールを通じて情報を補完する。
これこそが ReAct の核心である:
Reason(推論):モデルが現在のコンテキストに基づいて次の一手を判断する
Act(行動):モデルがツール呼び出しの意図を発行する
Observe(観測):ツールの結果が messages に書き戻される
Reason(推論):モデルが新たな観測結果に基づいて判断を続けるこのサイクルを繰り返すことで、システムははじめて「仕事ができる」という印象を与えるのだ。
8. ツールの実行結果を必ず messages に追加しなければならない理由
ツールの実行が終わったあと、最も重要なステップは「結果を取得すること」ではなく、
結果をメッセージストリームに書き戻すことです。
たとえば、モデルが package.json の読み取りを要求したとします。ツールは実際にファイルの内容を読み取ったのに、その結果が messages に追加されなければ、次のターンでモデルはそれを認識できません。
すると、次のような奇妙な断絶が生まれます。
モデル:「package.json を読み取る必要があります」
システムが package.json を読み取った
次のターンのモデル:「まだ package.json に何が書いてあるかわからない」ツールの結果を messages に追加することは、本質的に ReAct の Observation を完了させることです。
外部世界の事実を、モデルが読めるコンテキストに翻訳し直すのです。
次のように捉えることもできます。
ツール呼び出しはモデルを現実世界に触れさせる。
messages への書き戻しは、モデルに「さっき何に触れたか」を記憶させる。前者がなければ、モデルは空想することしかできません。
後者がなければ、モデルは行動するたびに記憶を失います。
多くの最小構成のエージェントデモはツールを呼び出せているように見えても、長いタスクをこなせません。問題はたいていここにあります。Act はあるのに、信頼できる Observe → 書き戻し → 次の Reason がないのです。
最小構成のデモが長続きしないのも同じ理由です。モデルはツール呼び出しを開始できるのに、ツールの結果が次の推論に安定して戻っていかないのです。
9. 自動圧縮がツールの結果追加の後にある理由
参考図の最終ステップは次のようになっている。
圧縮が必要かチェックそして、これは「ツール結果を messages に追加」した後ろに置かれている。
この順序は非常に重要だ。
なぜなら、ツールの結果こそがコンテキスト膨張の主要な発生源だからだ。
ファイルを読む → 数百行のコードが返ることがある
テストを実行する → 長大なログが返ることがある
コードを検索する → 数十件のヒット位置が返ることがある
外部サービスを呼び出す → 巨大な構造化 JSON が返ることがあるこうした内容を毎回そのまま次のターンのモデル入力に詰め込んでいると、長いタスクはすぐに高コスト・低速・焦点喪失に陥ってしまう。
そのため、Claude Code はメインループの中で継続的に次の問いを立てなければならない。
現在の messages は、まだこのまま持ち回れるか?持ち回れないなら、圧縮する。
圧縮とは、内容を適当に削ることではない。後続のタスクにとって有用な情報をできるだけ残すことだ。
ユーザーの目標は何か?
すでに何を試したか?
どのファイルを読んだか?
どのコマンドを実行したか?
どのエラーがまだ未解決か?
次に注目すべきは何か?自動圧縮は「トークンを節約する小技」ではない。Agent が長大なタスクを走らせられるかどうかを決める基盤インフラなのだ。
圧縮がなければ、ReAct ループは頑張れば頑張るほどメッセージ履歴が制御不能になっていく。
圧縮戦略は Agent エンジニアリングの成熟度をよく表す。乱暴な切り詰めは重要な情報を落としやすく、過度な圧縮はモデルに「自分がすでに何をやったか」を忘れさせる。Context 管理の話題に入る際に、この点については改めて掘り下げていく。
10. ソースコードリーディングの観点から、このメインラインをどう追うか?
query.ts を読むときは、いきなり分岐に入り込まないこと。
より良いアプローチは、まず以下の 8 つの問いを押さえることだ。
1. QueryEngine はどこで生成されるのか?
2. submitMessage はどのように agent run を開始するのか?
3. State はどこで生成されるのか?
4. buildQuery は State からどの情報を取得するのか?
5. Model API の応答を受け取った後、コードはどのように tool use を識別するのか?
6. ツール呼び出しはどこで実行されるのか?
7. tool result はどのように messages へ追記されるのか?
8. いつ auto compact が発火するのか?この 8 つの問いを繋げられれば、query.ts と QueryEngine のメインラインの関係は明確になる。
さらに読み進めるなら、これらの問いをより具体的なソースコードのアンカーポイントに落とし込むとよい。
QueryEngine.ts
-> submitMessage を探す:ユーザー入力がどのように 1 ターンに入るか
query.ts
-> QueryParams を探す:1 回のクエリに必要な入力は何か
-> State を探す:ループ間で保持される状態は何か
-> queryLoop を探す:各ターンで messagesForQuery をどこで準備するか
-> tool_use 収集を探す:モデル出力がどのようにツール呼び出しリストになるか
-> ツール実行のエントリーポイントを探す:runTools / StreamingToolExecutor がどのように選択されるか
-> tool_result の埋め戻しを探す:ツール結果がどのように次ターンの messages にマージされるか
services/tools/StreamingToolExecutor.ts
-> ストリーミングツール実行と並行安全性がどのように連携するかを見る
services/tools/toolOrchestration.ts
-> バッチツール呼び出しが isConcurrencySafe によってどのようにグループ化されるかを見るこれらのアンカーポイントの背後には、同じ一本のエンジニアリング上のリンクが通っている。
messagesForQuery
-> model stream
-> assistantMessages + toolUseBlocks
-> toolResults
-> next State.messagesソースコード内の大量の分岐は、すべてこの連鎖に紐づけることができる。たとえば、プロンプトが長すぎる場合の復旧、最大出力トークン超過時の復旧、stop hook によるブロック、auto compact、memory prefetch、skill discovery といった機能は、本質的にはすべて同じ問いに答えている。すなわち、「このターンが正常に完了しなかったとき、次のターンの State をどう構築すべきか」という問いだ。
このファイルが本当に伝えたいのは、「特定の関数が極端に複雑である」ということではなく、きわめて安定したエンジニアリングパターンの存在であることに気づくだろう。
State
-> Query
-> Model Response
-> Tool Use?
-> Tool Result
-> Updated State
-> Next Queryこの連鎖をいったん理解すれば、後続の Tools、Context、Prompt、Memory、Permission はすべてここに紐づけられる。
Tools は行動層である。
Context はターンごとの Query を構成する材料の組み立てである。
Prompt はモデルに判断と行動のルールを伝えるものである。
Permission は行動の前に踏むブレーキである。
Compact は長時間タスクにおける容量管理である。
そして query.ts の ReAct ステートマシンこそが、それらすべての能力を一本の主軸としてつなぎ合わせる存在なのだ。
11. 参考図を Mermaid フローに描き直す
全体像を次のフローに圧縮できる。
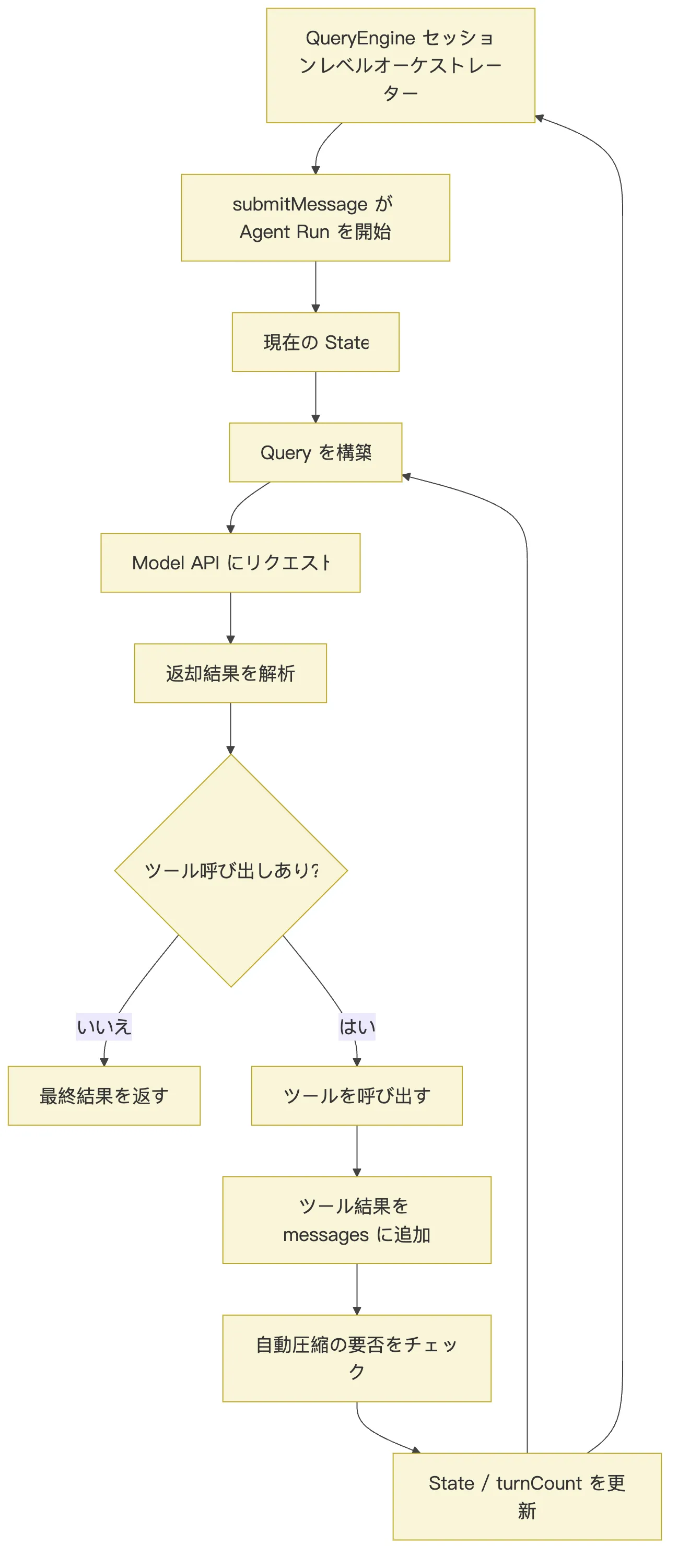
この図で最も覚えておくべきは二つのループだ。
一つ目は ReAct ループである。
Reason -> Act -> Observe -> Reason二つ目はエンジニアリング状態ループである。
QueryEngine -> State -> Query -> Response -> Tool Result -> State -> QueryEngine前者は、Agent がなぜ「考えながら動く」ように見えるのかを説明している。
後者は、ソースコードに QueryEngine、State、messages、toolUseContext、turnCount、autoCompactTracking、permissionDenials、totalUsage がなぜ必要なのかを説明している。
12. 一言でまとめる
query.ts の ReAct メカニズムは、本質的には絶えず進化する State を維持することにある。
各ラウンドで、Claude Code は現在の State をもとに Query を構築し、Model API にリクエストを送り、モデルがツールを呼び出すかどうかを解析する。モデルがツールを必要としなければ、最終結果を返す。モデルがツールを必要とするなら、システムはツールを実行し、その結果を messages に追加し、圧縮が必要かどうかをチェックし、更新された State を携えて次のラウンドに進む。
このループの外側では、QueryEngine がセッションレベルの状態を保持し、ツール・権限・コンテキスト・予算・キャッシュ・中断制御を、完全なタスクランタイムとして統合する。
つまり Claude Code は「モデルが一度だけ応答する」プログラムではなく、状態を軸に回る Agent ステートマシンなのだ。
モデルは次の一手を判断する。
ツールは実世界と接触する。
messages は実世界をモデルに持ち帰る。
圧縮は長いタスクを走り続けさせる。
State はこれらすべてを継続可能なループに組織化する。
QueryEngine はそのループをセッションレベルのランタイムに収める。この ReAct の閉ループを理解すれば、Prompt・Tools・Context 管理・マルチ Agent 連携も、バラバラなモジュールには見えなくなる。
それらはすべて、同一の目的に奉仕している。
モデルを「話せる」だけでなく、エンジニアリングの世界で一歩ずつ物事を成し遂げられる存在にすることだ。